
Processes for Elixir Fractals
by Jeremy D. Frens
on June 12, 2016
part of the
Fractals in Elixir
series
The story so far:
- The reboot — I wrote a Fractals program in Elixir, and it sucked. This new one won’t suck as much.
- The output process — I had a clever idea for ordering the output properly.1
This week, I have an overview of the processes I’m implementing in my app.
You can check out my code2 if you want to follow along.
A picture!
My program outputs a picture:

I kind of guessed at a simple formula for turning x-y coordinates into colors, and it looked good enough. I just need something that I can recognize each time I run the program.
My processes
These are the processes I thought I would need as of a few weeks ago:
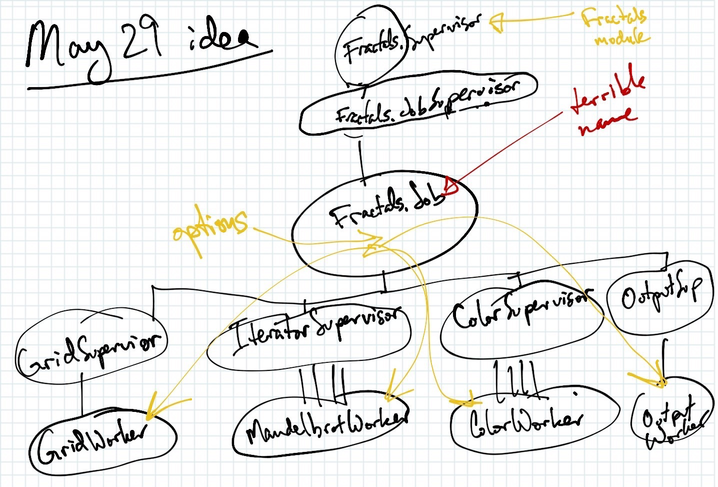
I was about to draw a fresh diagram when I realized I’m still implementing these processes with a few name changes. And the rough drawing and scribbled letters add a cool authenticity, right?
The supervision lines
Lines between ovals means supervision: the higher oval supervises the lower oval.
Some ovals have multiple lines between them; this means multiple children. It should pay to have multiple workers for these tasks. I’ll use pooling so that I don’t overwhelm the system with processes. I’ll probably need another process or two to manage the pooling.
Different workers
MandelbrotWorker actually represents multiple types of workers. I plan on having a different worker for each type of fractal: MandlebrotWorker, JuliaWorker, BurningShipWorker, etc. The IteratorSupervisor3 will decide which workers to spawn based on the options passed to it.
Application supervisor
The Fractals.Supervisor is actually the Application for the project, defined in the Fractals module. All other processes are named after their module.
Simple one-for-one
Most Elixir apps will start up the app as a process. My app is no different. Unfortunately, the app is started as soon as we run the executable, then my CLI4 has a chance to read in the Options. But notice the yellow options that I pass into the Job for all of the workers. If the application starts all of those processes before I can parse the options, I’ll have to pass the options in later as a special call to the processes. I fear this would open up some race conditions or other problems.
Elixir provides a simple one-for-one supervision strategy. This is an odd bird. All other strategies will start their children right away, but a simple-one-for-one supervisor does not. You describe what one child looks like in the supervisor:
supervise([worker(Fractals.Job, [])], strategy: :simple_one_for_one)
Later you ask for a child to be spawned:
Fractals.JobSupervisor.start_child(options)
You can dynamically start multiple children this way. I just need the one started dynamically so that I can pass in the options.
The options
But what if I passed the options around in the chunks (which was my original plan)? This way a chunk would provide the process with everything it needed to know to do its work. Each chunk a process got might be for a different fractal.
However, the output process (which I wrote about last week) does not get everything it needs to know from the options. It needs to keep track of the which chunk should be output next based on its chunk number. This “current chunk number” can’t be part of the options itself; the whole idea is that the output worker is the only process that really knows which chunk should be output next.
I could use a Map to associate an Options with a “current chunk number”, but I don’t think I could get this to work with my selective receive (which also I blogged about last week).
Today’s implementation
I have everything implemented except for the IteratorSupervisor and its workers. So everything except for the fractals themselves!
The GridWorker generates a real grid of complex numbers (pun intended). Much of this I took from my previous app, I just put a GenServer worker on it and a supervisor watching the worker. The Grid module has some good specs.
The ColorizerWorker (named ColorWorker in the diagram) is done even though the escape-time algorithm isn’t implemented yet. It’s totally ignorant about where its data comes from, so it doesn’t matter that it all comes from GridWorker for now. And it has the Colorizer module do all the interesting work. So it’s Colorizer that will have to change when the escape-time algorithms are implemented. (It’ll get specs then, too.)
The OutputWorker just got a few minor refactorings from last time.
Integration spec
As I looked at ColorizerWorker, I realized that it was done (as I mentioned above). So I wanted to test it. ColorizerWorker.colorize/2 is pretty testable, but it’s not really an interesting function to test. Plus, it maybe should go in Colorizer itself.
Everything else in the worker needs me to start up the worker along with an OutputWorker. It can be done, but it seemed like a little more work than I wanted to do. I thought about mocking out the call to OutputWorker.write/2, but I just couldn’t get it to work correctly.
Then I realized that the worker wasn’t really anything special. It doesn’t have any interesting edge cases. So was it really wortcoming up with a unit spec for it? Not really. Colorizer will have its own specs when it starts doing something interesting. ColorizerWorker can be tested with an integration test.
So I wrote an integration spec. I wanted to integrates as much of the app as possible, so it goes from input file to output file through a helper function in CLI.
I learned a couple of interesting things about my app and about processes and about the way I’m testing my code. I’ll talk about these discoveries in future posts.
The important thing is that the integration spec is a great success, and it gives me confidence that the ColorizerWorker is working.5
Things that will change
OutputWorker is a GenServer
I’m pretty sure the OutputWorker will eventually turn into a GenServer. I’ll lose my selective receive, but I have some other tricks to try. I’ve got a half-assed GenServer as it is, and the closer I bring it to being full assed, it’s going to look worse and worse. I’ll just end up implementing a GenServer by hand poorly.
Process-oriented programming, not object oriented
I suspect the options will end up in the chunks. Passing them into the processes just feels too object oriented to me. If I wanted to process multiple fractals at the same time, I’d have to create separate process tree starting at the Job process. This makes naming processes and pooling process a lot harder.
But being able to work on multiple fractals all concurrently just sounds awesome to me, real process-oriented programming.
Too much data
My app passes around a lot of data. My fractal file I use for manual testing has 787 chunks of 1000 data points sent out of each process, and there three processes sending out data.
When a message is sent from one process to the other, the data is copied into the other process. That takes time.
One thought I had was to store the data in an Agent. A pid is much easier to copy from process to process. Plus, I could update the data in-place in the agent.
Next Time
I’ll probably talk about stuff I discovered while writing the integration spec next week. This spec really made me question my writing my own process handling for OutputWorker.
After that, I should have the basic app completed, and so I’ll probably write about the raw computations (and ignore the processes).
Footnotes
-
Apparently, it’s a well-known clever idea, and some people don’t like it. I’ll probably have to abandon the clever idea anyway for other reasons. ↩
-
My
mandelbrotrepo is on GitHub. Read the README for instructions on compiling and running the Elixir program. You can also peruse the code through your browser:https://github.com/jdfrens/mandelbrot/tree/blog_2016_06_12/elixir. ↩ -
“Iterator” is a bad name. An “iterator” is a data structure in most languages usually over enumerable types. I don’t mean that at all here. It’s just a term I starting using in the old app, and it’s been grandfathered into the new app. I should be using a term like “escape-time algorithm”, but
EscapeTimeAlgorithmSupervisoris a bit of a mouthful. ↩ -
I will often omit the
Fractalsnamespace when referring to my modules.CLIis actuallyFractals.CLI. I’ll try to remember to useFractalsif there’s an ambiguity. ↩ -
Somewhat ironically, my integration spec gives me less confidence in
Colorizerbecause the output of my puny 2x3 image is all black. There should be some color in it, I think. But that’s just it: I don’t really want to testColorizernow. It’s doing computations that I’ll throw away when the escape-time algorithms are implemented. (And they will be implemented soon, otherwise why would this project exist?) The output I get for a larger image is fine, so I’m not going to worry about it for now. ↩